
Microservice architecture is a new standard for enterprise software development architecture. It’s complex to learn and understand. But once you master it, you’ll enjoy using it.
Good microservice architecture should have at least these components:
- API Gateway
- Discovery Service
- Centralized Configuration
- Business Services
So, let’s take an example and study it.
Let’s assume we need a system where we will store information about authors and books. Each author can have written multiple books. Authors can publish new books, and our system should update this information.
For this, we will need two services – author service and book service. We will also need other components mentioned above to make our system production-ready with the microservice architecture.
So, our final components and services list would look like this:
- API Gateway
- Discovery Service
- Centralized Configuration
- Author Service
- Book Service
Our business services are book service and author service. So, let’s draw an architectural diagram and elaborate on each service one by one.
Microservice Architectural Diagram
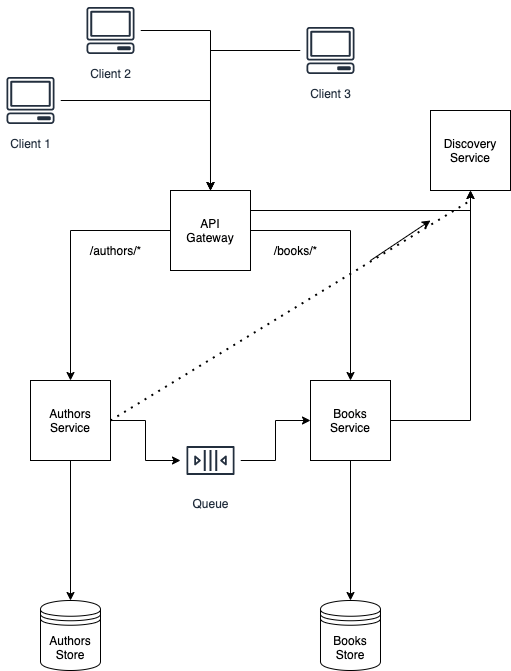
In this architectural diagram, all services are drawn with their own data stores. Only configuration service was not drawn in this diagram to not complicate it more. But think of it as a place where all the other services – book service, author service, API Gateway, and discovery service have their configuration properties. We will walk through the centralized configuration in more detail in a later paragraph dedicated to it.
Each business service should have its own data store. They should not share databases, and data between them should be shared by either APIs or events. The queue shown in the diagram is an event. It could be triggered when we add a new author with its books. Author data will be saved in the author service database, and books will be sent to the book service to handle the data for books (e.g. save in database).
Each service can have a different database. For example, the author service could use a relational database such as MySQL while the book service could use a NoSQL database like DynamoDB.
Also, we can write each service in a different programming language. It is not necessary to write services in the same programming language.
Now, let’s dive more deep into each individual service.
What API Gateway Does?
API Gateway is a highly available service that is responsible for routing the traffic to the corresponding service. It should route the traffic to a particular business service depending on the request.
API Gateway is a critical component, and you should make sure it has high availability. It should also be resilient to failures.
API Gateway could also be responsible for authentication and verifying if the user/client has permission to make the particular request.
So, API Gateway is the entry point of clients’ requests. As per the diagram, clients send requests to API Gateway and it redirects traffic to the corresponding service. If the request is made with a URL /authors/ then the traffic would be routed to the author service. If the request is made with a URL /books/ then the traffic would be routed to book service.
For instance, our main domain is api.yourdomai.com, and DNS record redirects traffic to API Gateway. Suppose a client makes a request to api.yourdomai.com/books/load then traffic would be routed to book service. For now, it should be clear that if API Gateway receives a request on api.yourdomai.com/authors/create URL, it will redirect traffic to the author service.
But how API Gateway decides where to route traffic. This does discovery service, and it’s a topic which we’ll discuss in the next paragraph.
What Discovery Service Does?
In Microservice architecture, there are many services. And they should interact together through APIs or events. So, the discovery service is responsible for having information about all the services.
When a new service starts, it can register itself in the discovery service so that other services and API Gateway could know what this service exists.
When service starts (boots), it should register itself in the discovery service. Author and book service register themselves in discovery service when they start. In this way, they make themselves available to other services.
When a service registers itself in the discovery service, it registers important information such as on which port the service runs, what is its root path and so on.
So, this way, API Gateway knows that author and book services are running, on which ports they use. So, API Gateway has complete information to redirect traffic to the right service.
If services need to make requests to each other without API Gateway then they can know another service address and port with the help of discovery service.
So, the process is automated and when services interact together they don’t need to know each other port or IP address. This information is available in the discovery service. Translated into a programming language, you don’t necessarily need to specify a URL and port to make a request to another microservice.
So, the discovery service should be highly available so that services can interact together. If it’s down, newly started services will not be able to register in the discovery service and the system would be impacted.
What is Centralized Configuration?
A centralized configuration is a highly available service that holds all the configuration information about each individual service.
It’s where the author and book service store their configurations. Centralized configuration could be useful when you need to change configs of your microservice without releasing any service.
Though we can save configs inside the services themselves. But this is not a good practice because each time we change a config, we should deploy the service.
What are Business Services?
In our example, business services are the author and book. Future business services should have similar characteristics. They should have a separate data store, share data with the author and book service through APIs or events, and so on. They should also register themselves in discovery service, and external traffic to them should be routed through API Gateway.
Microservice Architecture Characteristics
Last but not least, let’s look at some characteristics of the microservice architecture.
- Each service should be testable and not dependant on other services.
- If one service fails other services should still function.
- Services should not share a database and should share data through APIs or events.
- We can write each service in a different programming language. In our example, the author service we could write on Java or JavaScript. And book service we could write on another programming language like Python or C#.
- Services can have different databases. It’s not necessary to use the same database technology for all the services.